
Ruth Rosenholtz
Visual Search
In scientific thought we adopt the simplest theory which will explain all the facts under consideration and enable us to predict new facts of the same kind. The catch in this criterion lies in the word ‘simplest’. It is really an aesthetic canon such as we find implicit in our criticisms of poetry or painting.
John Burdon Sanderson Haldane Possible Worlds (1927): Science and Theology as Art-Forms
Theories of Visual Search: The Old and the New
My lab’s work on visual search predominantly addresses visual aspects of search: can we predict, based on the visual characteristics of the display, how easy search will be? We aim to see how well one can do with a simple model of critical visual processing stages, coupled with ideal or semi-ideal (ideal + limits) decision stages.
Below are descriptions of three “generations” of research into visual search in my lab. The first section describes our current view of search, based on recent research in the lab on peripheral vision, particularly crowding. The second and third sections describe older work in the lab: the Statistical Saliency Model, which postulated that the visual system had an interest in detecting and quickly examining outliers; and my cautionary tale that one should not make too much of search asymmetries, because it is tricky to ensure that one’s experimental design did not asymmetrically give an advantage to some search conditions over others.
THIS PAGE UNDER CONSTRUCTION
Visual Search: Strengths and Limitations of Peripheral Vision, or Presence/Absence of Basic Features?
Intriguingly, search is sometimes difficult even when an observer can clearly distinguish the search target from the other items in the display, known as “distractors”. For example, search for a randomly oriented T among randomly oriented Ls is difficult (Wolfe, Cave, & Franzel, 1989), even though we can easily tell an individual T from an L. Similarly, search for a target defined by a conjunction of features – such as a white vertical bar among black verticals and white horizontals – is difficult relative to a “feature” search for a horizontal bar among verticals, or for a white bar among black (Treisman & Gelade, 1980; Treisman & Schmidt, 1982). These phenomena imply that vision is not the same everywhere. If it were, the easy discriminability of a focal target and distractor pair should lead to easy search.
In what way is vision not the same everywhere? Popular models of search have focused on potential differences between attended and unattended vision. This includes not only theories such as the seminal Feature Integration Theory (Treisman & Gelade, 1980), and later Guided Search (Wolfe, 1994), but is also at least implicit in many other theories of search (e.g. Itti et al, 1998; Rosenholtz, 1999; Li, 2002; Torralba et al, 2006; Zhang et al, 2008). According to such theories, unattended vision has access only to “basic features” like orientation, color, and motion. Therefore, a key factor determining task difficulty consists of whether or not the search target contains a “basic feature” not found in the distractors.
However, an important way in which vision is not the same everywhere concerns the difference between the fovea and the periphery. Clearly peripheral vision is important in visual search. The periphery, being much larger than fovea, is inherently more likely to contain the target, and typically the target is peripheral until it is found. We have argued that search performance is constrained less by the capabilities of preattentive vision than by the abilities and limitations of peripheral vision. We have shown that one can predict the difficulty of a search task by measuring the discriminability of target-present from target-absent patches in the periphery. Furthermore, we have developed a model of peripheral vision, known as the Texture Tiling Model, and shown that this model can predict not only peripheral d’ but also relative search difficulty for a range of classic search conditions.
In addition, some search results have seemed in conflict with the FIT story about basic features. Observers can quickly search among shaded cubes for one lit from a unique direction. However, replace the cubes with similar 2-D patterns that do not appear to have a 3-D shape, and search difficulty increases. These results have challenged models of visual search and attention, since such models have typically suggested that the “basic” features that lead to efficient search are lower level (orientation, motion, color) than lighting direction or 3-D shape. We have shown that the same texture tiling model that predicts search difficulty for classic search conditions described above can also predict difficulty of these cube search tasks and their 2-D “equivalents”. This suggests that cube search displays differ from those with “equivalent” 2-D search items, in terms of the informativeness of fairly low-level image statistics. This informativeness predicts peripheral discriminability of target-present from target-absent patches, which in turn predicts visual search performance, across a wide range of conditions. Comparing model performance on a number of classic search tasks, cube search does not appear unexpectedly easy. Easy cube search, per se, does not provide evidence for preattentive computation of 3-D scene properties.
We can discriminate between traditional models of search and our recent texture tiling model (TTM) (Rosenholtz, Huang, Raj, Balas, & Ilie, 2012b) by designing new experiments that directly pit these models against each other. We began with five classic experiments that FIT already claims to explain: T among Ls, 2 among 5s, Q among Os, O among Qs, and an orientation/luminance-contrast conjunction search. We then made fairly subtle changes to these search tasks. We made search items out of thinner or thicker bars, or lengthened or moved one of the component lines. We found that these changes lead to significant changes in performance, in a direction predicted by TTM, providing definitive evidence in favor of the texture tiling model as opposed to traditional views of search.
The Statistical Saliency Model: The Visual System Looks for Outliers
The intuition behind much of my work on visual search is that the visual system has an interest in noticing “unusual” items, where “unusual” can mean “unlikely to have been drawn from the same statistical process as the stuff in the surrounding regions,” or it might also mean the more general, “I wasn’t expecting to see that.” Based upon this intuition, I have proposed the Statistical Saliency model for visual search, and shown that this model predicts a wide range of search results.
The Statistical Saliency Model: First represent the search display in an appropriate feature space (this is the part that can be tricky for complex targets and distractors). Then compute the saliency by essentially doing a test for outliers. For a 1-D feature, like perhaps length, or contrast energy, this looks like computing a z-score:
Saliency, Δ = (T – μD) / σD Here, T is the target feature, μD is the local mean of the distractors, and σD is the standard deviation of the distractors.
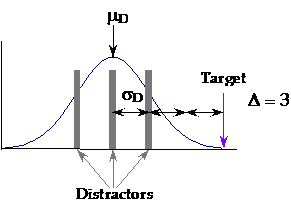
As shown in Figure 1, this amounts to counting the number of standard deviations between the target feature value and the mean of the distractors. (This mean is local, so neighboring items have more effect than more distant items.) The larger the saliency, the easier the predicted search. Essentially this is like representing the distractors with the best-fit normal distribution (shown in dark blue in Figure 1), and asking how likely the target is to have come from that distribution.
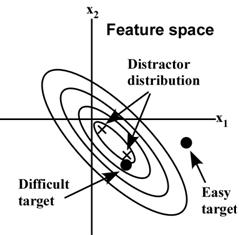
For higher-dimensional features such as velocity (vx, vy), color, etc., the model computes the Mahalanobis distance,
Δ = sqrt[(T – μD)’ ΣD-1 (T – μD)],
between the target, T, and the mean of the distractors. Here ΣD is the covariance matrix of the distractors, and T and μD are now vectors. As shown in Figure 2, this again amounts to counting the number of “standard deviations” between the target and the mean of the distractors, but in the multi-dimensional case this involves counting the number of covariance ellipsoids.
{kind=link}
{kind=link}
The Statistical Saliency model can also be thought of as formalizing the rule of thumb suggested by Duncan & Humphreys (1989): search is easier when target-distractor similarity decreases, or when distractor-distractor similarity increases.
More recent work in our lab, in conjunction with Zhenlan Jin and Alvin Raj, has implemented this saliency model so that it can operate on arbitrary images as input. This includes extracting motion saliency from video, and work demonstrating that saliency is predictive of where people look in video out the windshield of a car, and of time to detect a pedestrian about to cross the road.
Viewed in light of our newer work on search and peripheral crowding, we view the old Statistical Saliency Model as descriptive; an attempt to predict with a simple model what stimuli would survive crowding and thus be easy to search for.
Search Asymmetries: Is There a Simpler Explanation?
My human vision work in general is motivated by the desire for simple predictive models of visual phenomena, which can then be easily applied to such things as image coding, and design of user interfaces and information visualizations. The Statistical Saliency model fits into this framework.
One difficulty in creating a simple model of visual search is that many early search results demonstrated search asymmetries. If the visual system requires a number of asymmetric mechanisms, this makes things difficult for modelers, since one must uncover all the mechanisms to have a reasonable model of visual search, and models will tend to need a new component for each asymmetric mechanism. If this is the way the visual system is, then we need to accommodate it, of course. But I have suggested that a number of visual search experiments which gave asymmetric results were actually asymmetrically designed, and thus no asymmetric mechanism are necessary to explain the results.
Bibliography
- Effects of temporal and spatiotemporal cues on detection of dynamic road hazardsWolfe, B., Kosovicheva, A., Stent, S., Rosenholtz, R., CR:PI, 2021. Abstract PDF
- Those pernicious itemsR. Rosenholtz, Brain & Behavioral Sciences, 2017. Abstract PDF
- Search performance is better predicted by tileability than by the presence of a unique basic featureChang, H., Rosenholtz, R., Journal of Vision, 2016. Abstract PDF
- Capabilities and limitations of peripheral visionRosenholtz, R., Annual Review of Vision Science, 2016. Abstract PDF
- Cube search, revisitedX. Zhang, J. Huang, S. Yigit-Elliott, and R. Rosenholtz, Journal of Vision, 2015. Abstract PDF
- A summary statistic representation in peripheral vision explains visual searchR. Rosenholtz, J. Huang, A. Raj, B. J. Balas, and L. Ilie, Journal of Vision, 2012. Abstract PDF
- Rethinking the role of top-down attention in vision: Effects attributable to a lossy representation in peripheral visionRuth Rosenholtz, Jie Huang, and Krista A. Ehinger, Front. Psych., 2012. Abstract PDF
- Visual search for arbitrary objects in real scenesJeremy M. Wolfe, George A. Alvarez, Ruth Rosenholtz, Yoana L. Kuzmova, Ashley M. Sherman, AP&P, 2011. Abstract PDF
- The effect of background color on asymmetries in color searchR. Rosenholtz, A.L. Nagy, N. R. Bell, Journal of Vision, 2004. Abstract PDF
- Visual search for orientation among heterogeneous distractors: Experimental results and implications for signal detection theory models of searchR. Rosenholtz, J. of Experimental Psychology, 2001. Abstract PDF
- Search asymmetries? What search asymmetries?R. Rosenholtz, Perception & Psychophysics, 2001. PDF
- A simple saliency model predicts a number of motion popout phenomenaR. Rosenholtz, Vision Research, 1999. Abstract PDF